torch.softmax() / torch.nn.Softmax()

A = torch.Tensor( [ [ -2 , -0.5 , 2.0 , 1.5 ] ,
[ -2 , -0.5 , 7.0 , 1.5 ] ])
p = torch.softmax(A , dim=1) # over rows
print(p)
# tensor([[1.0730e-02, 4.8089e-02, 5.8585e-01, 3.5533e-01],
# [1.2282e-04, 5.5046e-04, 9.9526e-01, 4.0674e-03]])
p = torch.softmax(A , dim=0) # over columns
print(p)
# tensor([[0.5000, 0.5000, 0.0067, 0.5000],
# [0.5000, 0.5000, 0.9933, 0.5000]])
# torch.nn.LogSoftmax() is taking logarithms of the result of softmax(xi)
# also we have torch.nn.Softmax()x is stored in one column, although it is represented in one line when typing it on the console.
x=torch.Tensor([ -2 , -0.5 , 2.0 , 1.5 ])
p=torch.softmax(x, dim=0)
print(p)
print(p.size())nn.Linear()
# input of size 5 and output of size 3
mod = nn.Linear(5,3,bias = True) # bias = True by default
print(mod)
# Linear(in_features=5, out_features=3, bias=True)
print(mod.weight)
print(mod.weight.size())
# Parameter containing:
# tensor([[-0.0636, 0.1377, -0.1297, 0.4385, 0.1840],
# [-0.4137, 0.2118, 0.2093, -0.0728, -0.2257],
# [ 0.4318, -0.1557, 0.1055, 0.3528, 0.2025]], requires_grad=True)
# torch.Size([3, 5])
print(mod.bias)
# Parameter containing:
# tensor([ 0.1466, 0.2684, -0.0493], requires_grad=True)
# change the weight of mod
with torch.no_grad():
mod.weight[0,0] = 0
mod.weight[0,1] = 1
mod.weight[0,2] = 2
print(mod.weight)vanilla nn
class two_layer_net(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(two_layer_net , self).__init__()
self.layer1 = nn.Linear( input_size, hidden_size , bias=True)
self.layer2 = nn.Linear( hidden_size, output_size , bias=True)
def forward(self, x):
x = self.layer1(x)
x = torch.relu(x) # relu activation function
x = self.layer2(x)
p = torch.softmax(x, dim= 0) # can be modified to meet your demands
return p
net = two_layer_net(2,5,3)
# Alternatively, all the parameters of the network can be accessed # by **net.parameters()**.
list_of_param = list( net.parameters() )
print(list_of_param)
# [Parameter containing:
#tensor([[10.0000, 20.0000],
# [ 0.0500, -0.5119],
# [-0.1930, -0.1993],
# [-0.0208, -0.0490],
# [ 0.2011, -0.2519]], requires_grad=True),
# Parameter containing:
# tensor([ 0.1292, -0.3313, -0.3548, -0.5247, 0.1753], requires_grad=True),
# Parameter containing:
# tensor([[0.3178, -0.1838, -0.1930, -0.3816, 0.1850],
# [ 0.2342, -0.2743, 0.2424, -0.3598, 0.3090],
# [ 0.0876, -0.3785, 0.2032, -0.2937, 0.0382]], requires_grad=True),
#Parameter containing:
# tensor([ 0.2120, -0.2751, 0.2351], requires_grad=True)]nn.NLLLoss()
负对数似然损失函数(Negtive Log Likehood)
a = torch.Tensor([[1,2,3]])
nll = nn.NLLLoss()
target1 = torch.Tensor([0]).long()
target2 = torch.Tensor([1]).long()
target3 = torch.Tensor([2]).long()
n1 = nll(a,target1)
# tensor(-1.)
n2 = nll(a,target2)
# tensor(-2.)
n3 = nll(a,target3)
# tensor(-3.)nn.NLLLoss()取出a中对应target位置的值并取负号,比如target[1]==0,就取a中index=0位置上的值再取负,作为NLLLoss的输出
nn.CrossEntropyLoss()
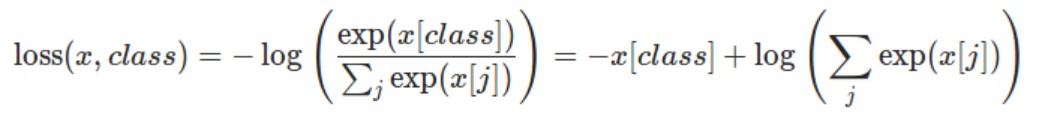
mycrit=nn.CrossEntropyLoss()
labels=torch.LongTensor([2,3])
scores=torch.Tensor([ [-1.2, 0.5 , 5, -0.5],
[1.4, -1.7 , -1.3, 5.0] ])
average_loss = mycrit(scores,labels)
print('loss = ', average_loss.item() )
# loss = 0.023508397862315178CrossEntropyLoss = Softmax + Log + NLL
softmax_func=nn.Softmax(dim=1)
soft_output=softmax_func(input)
log_output=torch.log(soft_output)
nllloss_func=nn.NLLLoss(reduction='none')
nllloss_output=nllloss_func(log_output, y_target)epoch
for epoch in range(15): # Do 15 passes through the training set
shuffled_indices=torch.randperm(60000)
for count in range(0,60000,bs):
optimizer.zero_grad()
# indices is a tensor, the following is slicing
indices=shuffled_indices[count:count+bs]
minibatch_data = train_data[indices]
minibatch_label = train_label[indices]
# pay attention on how to slice a tensorepoch + monitoring loss + time + lr update
start = time.time()
lr = 0.05 \# initial learning rate
for epoch in range(200):
# learning rate strategy : divide the learning rate by 1.5 every 10 epochs
if epoch%10==0 and epoch>10:
lr = lr / 1.5
# create a new optimizer at the beginning of each epoch: give the current learning rate.
optimizer=torch.optim.SGD( net.parameters() , lr=lr )
running_loss=0
running_error=0
num_batches=0
shuffled_indices=torch.randperm(60000)
for count in range(0,60000,bs):
# Set the gradients to zeros
optimizer.zero_grad()
# create a minibatch
indices=shuffled_indices[count:count+bs]
minibatch_data = train_data[indices]
minibatch_label= train_label[indices]
# send them to the gpu
device = torch.device("cuda")
net = net.to(device)
minibatch_data=minibatch_data.to(device)
minibatch_label=minibatch_label.to(device)
# reshape the minibatch
inputs = minibatch_data.view(bs,784)
# tell Pytorch to start tracking all operations that will be done on "inputs"
inputs.requires_grad_()
# forward the minibatch through the net
scores=net( inputs )
# Compute the average of the losses of the data points in the minibatch
loss = criterion( scores , minibatch_label)
# backward pass to compute dL/dU, dL/dV and dL/dW
loss.backward()
# do one step of stochastic gradient descent: U=U-lr(dL/dU), V=V-lr(dL/dU), ...
optimizer.step()
# START COMPUTING STATS
# add the loss of this batch to the running loss
running_loss += loss.detach().item()
# compute the error made on this batch and add it to the running error
error = utils.get_error( scores.detach() , minibatch_label)
running_error += error.item()
num_batches+=1
# compute some stats
running_loss += loss.detach().item()
error = utils.get_error( scores.detach(), minibatch_label)
running_error += error.item()
num_batches+=1
# once the epoch is finished we divide the "running quantities"
# by the number of batches
total_loss = running_loss/num_batches
total_error = running_error/num_batches
elapsed_time = time.time() – start
# every 10 epoch we display the stats
# and compute the error rate on the test set
if epoch % 10 == 0 :
print('epoch=',epoch, ' time=', elapsed_time,
' loss=', total_loss , ' error=', total_error*100 ,'percent lr=', lr)
eval_on_test_set()Evaluate on test set
def eval_on_test_set():
running_error=0
num_batches=0
for i in range(0,10000,bs):
minibatch_data = test_data[i:i+bs]
minibatch_label= test_label[i:i+bs]
inputs = minibatch_data.view(bs,784)
scores=net( inputs )
error = utils.get_error( scores , minibatch_label)
running_error += error.item()
num_batches+=1
total_error = running_error/num_batches
print( 'test error = ', total_error*100 ,'percent')
